
AST: Audio Spectrogram Transformer
The paper can be accessed from here
This paper is the first convolution-free, purely attention-based model for audio classification.
Background
- CNN have been widely used to learn representations from raw spectrograms for end-to-end modelling
- Add a self-attention mechanism on the top of the CNN to better capture long-range global context
- Have achieved state-of-the-art (SOTA) results for many audio classification tasks
- The success of purely attention-based models in the vision domain
Addressed problems
- CNN-based models typically require architecture tuning to obtain optimal performance for different tasks.
- SOTA CNN-attention hybrid models have more complicated architecture with lots of parameters.
Research Aim
- Build a convolution-free, purely attention-based model for audio classification which features a simple architecture and superior performance.
- Achieve better performance with a simpler architecture with fewer parameters.
Model Structure
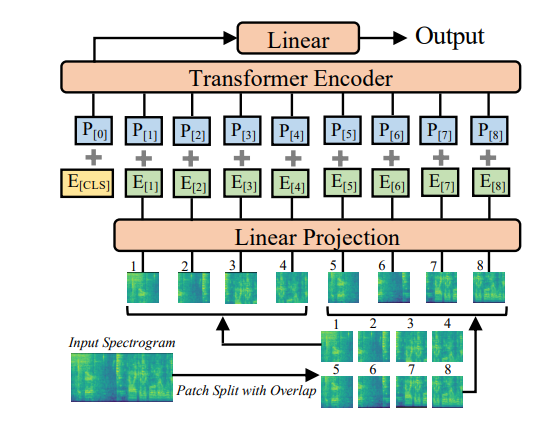
- The input audio waveform of t seconds is converted into a sequence of 128-D log Mel filterbank features computed with a 25 ms Hamming window every 10ms. (128 * 100t spectrogram)
- Split the spectrogram into a sequence of N 16 * 16 patches with an overlap of 6 in both time and frequency dimension
- Flatten each 16 * 16 patch to a 1D patch embedding of size 768 using a linear projection layer
- Add a trainable positional embedding (size 768) to each patch embedding
- Append a [CLS] token at the beginning of the sequence
- Propose an approach for transferring knowledge from the Vision Transformer (ViT) pretrained on ImageNet to AST
- propose a cut and bi-linear interpolate method for positional embedding adaptation.
Experiments
Datasets
- AudioSet – a collection of over 2 million 10-second audio clips contains from a set of 527 labels
- ESC-50 – consists of 2,000 5-second environmental audio recordings organized into 50 classes
- Speech Commands V2 – consists of 105,829 1-second recordings of 35 common speech commands
Focused Tasks
-
Use weight averaging strategies
-
Use ensemble strategies
Ensemble-S: run three times with the exact same setting, but with a different random seed.
Ensemble-M: ensemble the three models in Ensemble-S together with another three models trained with different patch split strategies.
-
Compare AST with the SOTA models in two setting
AST-S: train an AST model with only ImageNet pretraining
AST-P: train an AST model with ImageNet and AudioSet pretraining
Evaluation metrics
- Mean average precision (mAP)
Additional experiments and analysis
- Impact of ImageNet Pretraining: ImageNet pretraining can greatly reduce the demand for in-domain audio data for AST.
- Impact of Positional Embedding Adaptation: reinitializing positional embedding does not completely break the pretrained model, but it leads to a noticeable performance drop. Bi-linear interpolation and nearest-neighbor interpolation do not result in a big difference.
- Impact of Patch Split Overlap: the performance improves with the overlap size for both balanced and full set experiments.
- Impact of Patch Shape and Size: when the area of the patch is the same (256), 128 * 2 rectangle patches perform better than 16 * 16 square patches. But considering there is not 128 * 2 patch based ImageNet pretrained models, using 16 * 16 patches is still the current optimal solution.
Summary
- AST feature a simple architecture and superior performance
- The final performance of AST on all three datasets indicated the potential for AST use as a generic audio classifier.